
Vous souhaitez poser les bases d’une bonne stratégie de référencement sur les moteurs de recherches et ainsi acquérir plus de trafic qualifié sur votre site web ?
Cela passe entre autre par le fichier robots.txt, qui est un fichier au format texte listant une série d’instructions destinées aux robots d’indexation tels que le Googlebot, afin de leur indiquer les zones de votre site où ils ne doivent pas aller.
Ce fichier est exclusivement pour les robots d’indexation et en aucun cas il n’interdit l’accès d’une de vos pages ou d’un de vos répertoires à un internaute.
Sitemap: https://www.exemple.fr/sitemap.xml
User-agent: *
Disallow: /pre-registration*
Disallow: /send-pre-registration*
Disallow: /fr/legal
Disallow: /en/legal
Disallow: /legal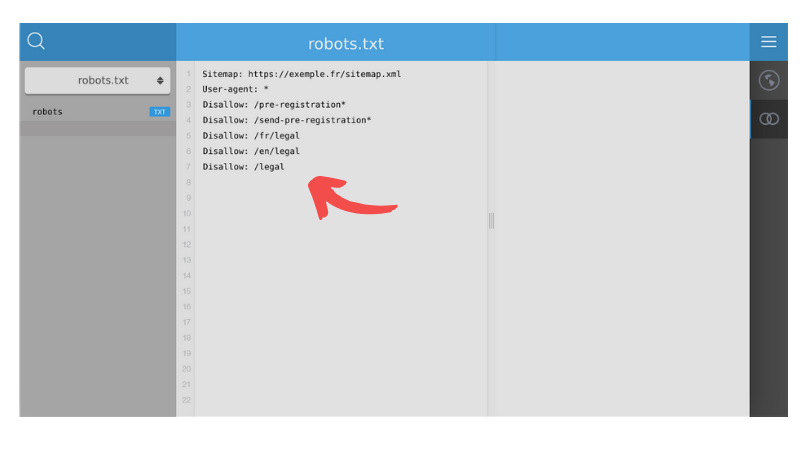
La plupart des moteurs de recherche (englobant Google, Bing et Yahoo) reconnaissent et respectent les instructions du fichier robots.txt.
Sommaire:
Vous avez besoin d’un fichier robots.txt
Configurez et optimisez votre fichier robots.txt pour le référencement
Fin de la prise en charge du noindex par Google au 1er Septembre 2019
Pourquoi le fichier robots.txt est-il important, voire indispensable et comment peut-il contribuer à améliorer votre référencement naturel ?
1. Vous avez besoin d’un fichier robots.txt
Vous n’arrivez pas à vous imaginer les situations où vous pourriez avoir besoin de déréférencer certaines pages de votre site web ? Les raisons sont bien réelles et peuvent être multiples:
- Indiquer quels robots d’exploration sont autorisés à crawler votre site web (Googlebot, bingbot, Yahoo ! Slurp…)
- Bloquer l’accès à vos pages privées
- Empêcher l’indexation de certains de vos fichiers (CSS, scripts ect…)
- Maximiser votre budget crawl
En configurant correctement le fichier robots.txt, vous n’aidez pas simplement vos utilisateurs mais vous capitalisez également pour le SEO et le bon référencement de votre site web sur les moteurs de recherche.
2. Configurez et optimisez votre fichier robots.txt pour le référencement
La configuration du fichier robots.txt est relativement simple et se fait en général en une seule fois à l’aide d’un éditeur de texte (Nodepad ++, Bloc-notes…). Mais vous pouvez y faire des mises à jour si cela est nécessaire.
Et dans ce cas nous vous conseillons vivement d’une part de vérifier vos modifications avant soumission du nouveau fichier robots.txt, mais également d’utiliser un outils de suivi de positions tels que celui d’octopulse.io en guise de surveillance.
En effet une erreur sur une ligne pourrait avoir de lourdes conséquences sur votre SEO.
a. Les directives les plus utilisées dans le fichier robots.txt :
- User-agent: [obligatoire, un ou plusieurs par groupe] : nom d’un robot de moteur de recherche (logiciel de robot d’exploration) auquel la règle s’applique
- Disallow: [au moins une ou plusieurs entrées Disallow ou Allow par règle] : répertoire ou page, relatifs au domaine racine, qui ne doivent pas être explorés par le user-agent.
- Allow: [au moins une ou plusieurs entrées Disallow ou Allow par règle] : répertoire ou page, relatifs au domaine racine, qui doivent être explorés par le user-agent mentionné précédemment.
- Sitemap: [facultatif, zéro ou plus par fichier] : emplacement d’un sitemap pour ce site Web. L’URL fournie doit être complète.
b. Où placer le fichier robots.txt
Votre fichier robots.txt doit obligatoirement être placé à la racine de votre site.

c. Quelques commandes du fichier robots.txt
Comment autoriser l’indexation de toutes les pages de votre site ?
User-agent: *
Disallow: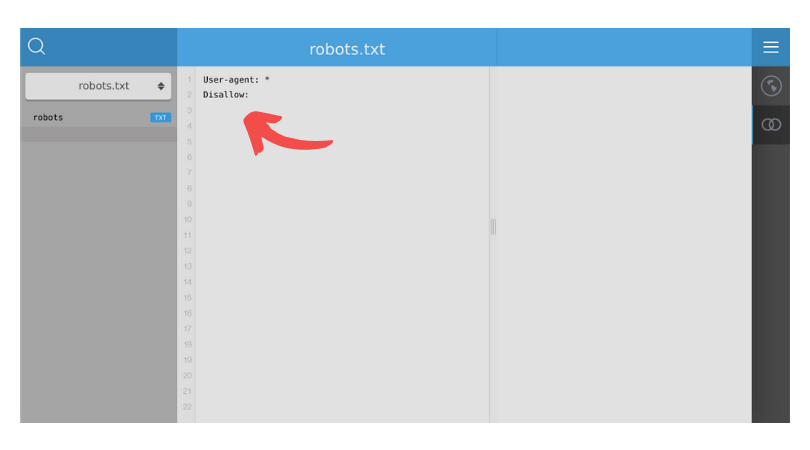
Comment bloquer l’indexation de toute les pages de votre site web ?
User-agent: *
Disallow: /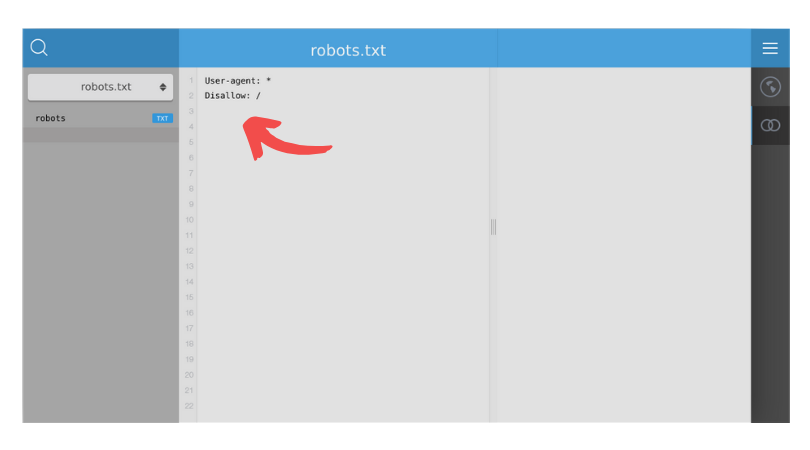
Comment bloquer l’indexation d’un dossier en particulier sur votre site web ?
User-agent: *
Disallow: /dossier/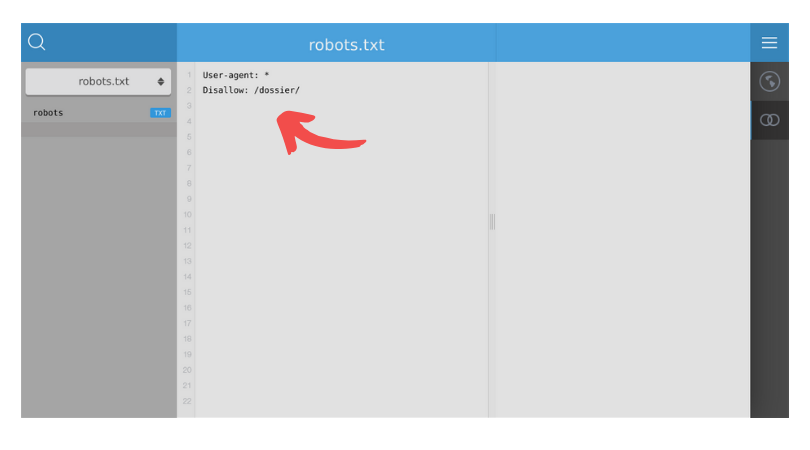
Comment bloquer Googlebot dans l’indexation d’un dossier, sauf pour une page spécifique dans ce dossier ?
User-agent: Googlebot
Disallow: /dossier/
Allow: /dossier/nompage.html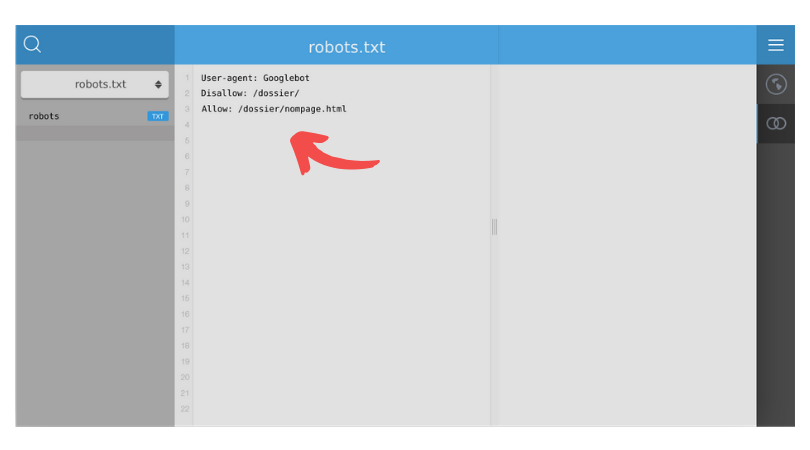
Vous devez avoir en tête lors de la configuration de ce fichier, que la facilité de crawl n’est pas un critère de pertinence de l’algorithme de Google à proprement parler.
L’effet sur le SEO n’est donc pas mécanique, a contrario de certaines balises html telles que la balise title ou la meta description.
Toutefois, une plateforme qui est explorée plus efficacement a évidemment davantage d’opportunités de voir ses contenus pertinents analysés et donc être visibles dans les résultats de recherche .
Ainsi, plus le contenu des pages indexées par les moteurs de recherche est pertinent et plus faible sera le taux de rebond.
Ce qui est un excellent signal envoyé aux robots des moteurs de recherche dans la mesure où vous leur indiquez de manière indirecte que vous vous souciez de l’expérience utilisateur.
De même, en donnant des instructions précises aux robots crawleurs, vous leurs indiquez de ne pas s’intéresser aux contenus dont vous pensez qu’ils n’apporteraient aucune valeur ajoutée dans les résultats de Google, Bing ou encore Yahoo.
Vous maximisez ainsi ce que l’on appelle votre budget crawl.
d. Maximisez votre budget d’analyse
Le budget crawl c’est la limite en termes de nombre de pages que va vous allouer un robot d’exploration pour le crawl de votre site web.
Si les robots des moteurs de recherche peuvent dépenser leur budget d’analyse à bon escient, ils organiseront et afficheront votre contenu pertinent dans les SERP de la meilleure façon possible, ce qui signifie que vous serez plus visible.
Toutefois, faites très attention à ce que les syntaxes que vous utilisez dans le fichier robots.txt soient toujours pris en compte par les robots d’indexation auxquels elles sont adressées.
3. Fin de la prise en charge du noindex par Google au 1er Septembre 2019
Google a annoncé la fin de l’interprétation, par ses bots, de plusieurs déclarations utilisées par certains webmasters – notamment crawl-delay, noindex et nofollow.
a. Quelles sont les implications pour votre site web ?
Vous risquez purement et simplement de voir des pages que vous souhaitiez déréférencer pour des raisons de confidentialité ou d’optimisation du budget crawl se retrouver dans les résultats de Google.
Il est donc plus que nécessaire d’éviter l’indexation de ces pages via des méthodes alternatives.
b. D’autres méthodes de désindexation sont possibles
- Ajouter le noindex dans les meta tags de la page (meilleure solution)
- Utiliser les codes HTTP 404 et 410 qui indiquent que la page n’existe pas, les crawlers de Google le comprennent et suppriment ces pages de son index
- Mettre une page ou un répertoire en Disallow via le robots.txt reste une possibilité
- Les pages placées derrière un verrou d’accès payant – et celles qui nécessitent un mot de passe – sont « en général » supprimées dans l’index de Google
Votre fichier robots.txt est-il donc bien configuré et est-il en conformité avec les nouvelles spécifications des robots crawleurs de Google qui seront en vigueur au 1er Septembre 2019 ?
Vérifiez-le gratuitement sur octopulse.io
Vous connaissez d’autres méthodes pour pallier la fin de la prise en charge du noindex par Google ?
Partagez-les en commentaire avec le reste de la communauté Octopulse !
Laisser un commentaire
Vous devez vous connecter pour publier un commentaire.